Firebase Summit Extended 2018 Singapore was recently and I gave a talk on Firebase MLKit and TensorFlow Lite. If you've not used Firebase before, its a mobile platform by Google to make developing Android, iOS and webapps easier and quicker. Originally Firebase was Analytics, Admob and a database but has been expanding quite a lot over the last few years. One of the new additions to the Firebase family is MLKit. It makes it easier to use machine learning features in your app (both Android and iOS) without the hassle it might otherwise be.
Machine learning
Officially, the definition of machine learning is "a method of data analysis that automates analytical model building. It is a branch of artificial intelligence based on the idea that systems can learn from data, identify patterns and make decisions with minimal human intervention". I'm not sure I understand that definition, I think an easier way to understand what ML is, is to compare it to traditional programming. In traditional programming, the human writes the program and has some data and then uses the computer to get some outputs. This could be for example writing a program to detect what fruit is in a photo. The programmer might write rules like "if it's round and red then its an apple" and "curved shape and yellow coloured is a banana". "round shaped and orange coloured is an orange". This pretty quickly becomes really complicated when adding more things to detect or more ways to detect them by (how do you even tell a computer that something has a curved shape?).
Machine learning is basically flipping this around. Instead of writing the rules for the program, you give the computer the inputs and the outputs and use a lot of compute power and the computer will "learn" how to match the inputs to the outputs on its own without the programmer having to write each and every rule. The process of training a model requires a lot of processing power and some ML expertise to design the model to do well for the task. Luckily Firebase already has models for some common tasks and as I'll get to later, there are easier ways to re-train a model too.
MLKit
There are a number of Ready to use models. For most of them there is an on-device and a cloud version of the model. The cloud models are bigger and more accurate but slower than the on-device models since the data needs to be uploaded to the cloud first. The cloud models are also not free. There are a few free calls per month but after that they cost. An example of the cloud vs on-device models is the image labelling API, on-device is trained on 400 labels and the cloud model has 10,000 and the first 1000 uses per month are free. Which one to use would depend quite a lot on the specific use-case and if the 400 labels are enough.
In my talk I demoed the MLKit Android Codelab and showed the MLKit FaceDetection API. There are several modes it can do, the simplest is just find the faces. The more complicated modes can detect the contours of the face (shape of face, eyes, nose, mouth). It can also return the facial expression (smiling, eyes open etc). Detection on device is fast enough to be able to detect on the frames of a video.
I recommend playing with the codelab, its simple to follow and set up and play with. These codelabs are better done on device than in the Android Emulator, I was getting initialization errors in the emulator when I tried it.
Custom TensorFlow Lite models
TensorFlow Lite is a stripped down version of regular TensorFlow that is aimed at running on mobile devices. It can only be used for inference, training will still require big TensorFlow and Lite is a little less flexible but in giving up that, you can run TensorFlow Lite on significantly smaller devices. For a comparison, the shared library (not RAM usage, just the lib, RAM will be a lot more) full tensorflow on my computer is ~200MB, whereas TFLite is ~2MB.
Building and using TFLite from scratch is not too difficult but Firebase MLKit does it all much easier and is cross platform so will work on both Android and iOS and automatically takes advantage of any hardware acceleration the device has.
There is another codelab that covers TFLite called TensorFlow for Poets 2. It is a simple camera app that detects different kinds of flowers. It's important to follow the right codelab, there have been several versions of TensorFlow for Poets. The old v1 is long outdated and there are 2 versions of v2, one uses TFMobile which is deprecated and will eventually be removed from TensorFlow in favour of TFLite. The one to use is v2 tflite that I linked above.
Transfer Learning
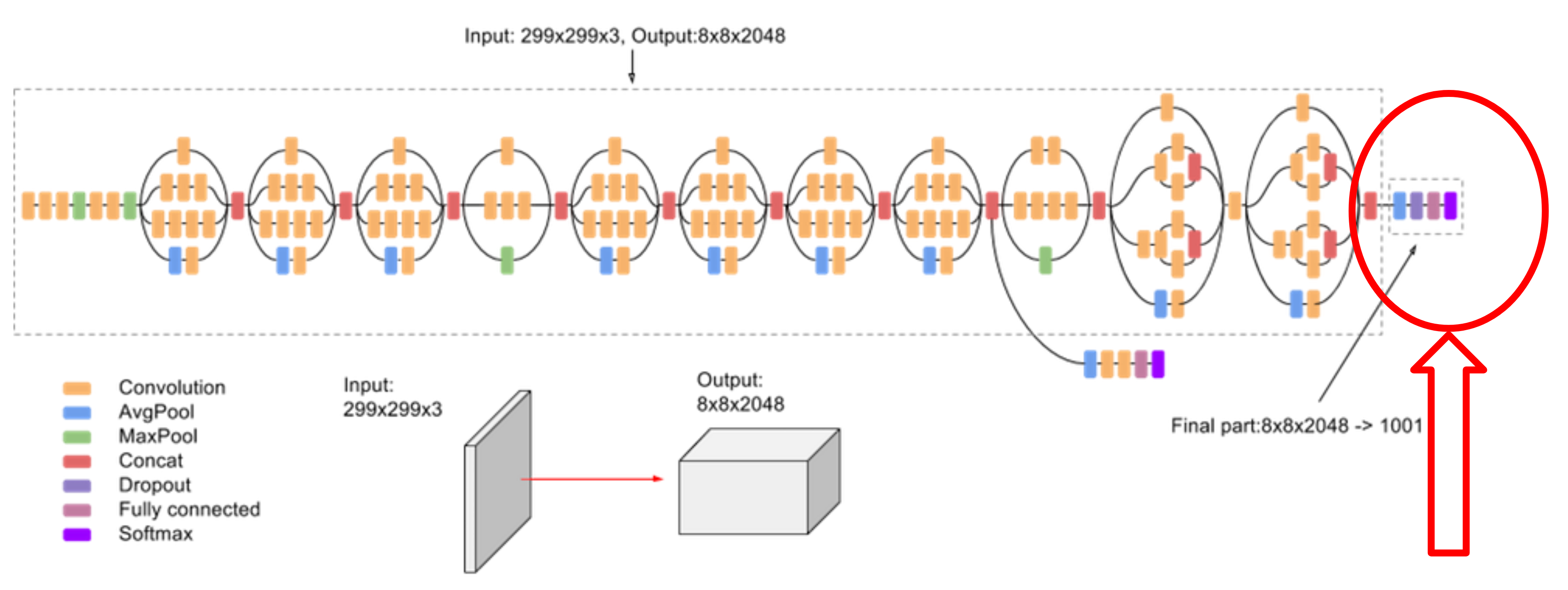
Transfer Learning is the thing that makes this codelab so easy. Here is a diagram of the Inception architecture that is commonly used for image recognition tasks. The lower levels of these networks are quite generic and detect generic features of images, and the last few layers take in those features and have output neurons for each class. Training the whole network would take ages since its pretty big. Luckily, there is a trick that will speed things up for us, we can take the pre-trained weights for the model and throw away only the last layer and train our own. This "transfering" of weights is where the name Transfer Learning comes from. (We'll actually be using the MobileNet model but the Inception architecture image was prettier and easier to explain.)
The flowers in the codelab are fine but what I really wanted to do was try and make the SeeFood app from the TV show Silicon Valley. I did the codelab like normal first to make sure everything was working and then went to figure out how to make it detect hotdogs vs not hotdogs.
To re-train the model we'll need images in two classes: 'hotdog' and 'not hotdog'. I found a fantastic kaggle dataset that had already organized a bunch of images and sorted them into two folders so grab that from here.
When you checkout the repo, there is a tf_files/retrained_labels.txt file
which lists the classes that the model will use. Edit that file so it has only
two lines, one class name on each line. Then put the train folder from the
kaggle dataset into tf_files/hotdogs/ so you will end up with
tf_files/hotdogs/hot_dog/ and tf_files/hotdogs/not_not_dog/.
To train our new hotdog model run this:
export IMAGE_SIZE=224
export ARCHITECTURE="mobilenet_0.50_${IMAGE_SIZE}"
export STEPS=1000
python -m scripts.retrain \
--bottleneck_dir=tf_files/bottlenecks \
--how_many_training_steps=$STEPS \
--train_batch_size=500 \
--model_dir=tf_files/models/ \
--summaries_dir=tf_files/training_summaries/"${ARCHITECTURE}" \
--output_graph=tf_files/retrained_graph.pb \
--output_labels=tf_files/retrained_labels.txt \
--architecture="${ARCHITECTURE}" \
--image_dir=tf_files/hotdogs
That will take a few minutes to run and then will output a new
tf_files/retrained_graph.pb file which is the trained version of the hotdog
model. Next we need to convert the protobuf file into TFLite's flatbuffer format by running:
export IMAGE_SIZE=224
tflite_convert \
--graph_def_file=tf_files/retrained_graph.pb \
--output_file=tf_files/optimized_graph.lite \
--input_format=TENSORFLOW_GRAPHDEF \
--output_format=TFLITE \
--input_shape=1,${IMAGE_SIZE},${IMAGE_SIZE},3 \
--input_array=input \
--output_array=final_result \
--inference_type=FLOAT \
--input_data_type=FLOAT
Then just copy the optimized_graph.lite into the android project and rebuild. Here is a screenshot of the final result :)

The slides from the presentation are here. Unfortunately there was no video recording of the talk.