If you've installed TensorFlow from pip, you've probably come across this message:
tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports
instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
Well, I did too and it got me wondering how much of a difference those instructions end up making. People often say GPUs are required for any non-trivial ML work so I wanted to see if that was really true. I decided to delve in and optimize TensorFlow and make it faster on my machine. I gave a talk about this yesterday at the TensorFlow and Deep Learning Meetup in Singapore, the slides will be attached at the end as well.
I recently packaged TensorFlow on Gentoo (you can install it with # emerge
tensorflow) and decided to compare it to the pip package to see how much of a
difference there would be. For the tests I didn't just want MNIST, I wanted
something a bit larger. I found the TensorFlow official models
repo and
thought ResNet would be big enough for some tests. ImageNet was a huge download
so I used CIFAR-10 instead. I also did a second smaller benchmark of a simple
tf.matmul() for a few different sized matrices. Matrix multiplication is
one of the most key parts of ML so I thought that would be interesting to see.
Benchmarks
I tested this on both my powerful workstation and my old laptop to get the spectrum of high-end and low-end. My workstation has an AMD Threadripper 1950x: 16 core / 32 thread, 3.4GHz base, 40MB cache total, and 32GB RAM. I also recently got an Nvidia 1080Ti from the guys at Lambda Labs to get TF properly working on Gentoo with CUDA so I'll also be comparing that. My laptop is a Haswell Core i7-4600U: 2.1GHz, 2 core / 4 thread, 4MB cache total, and 12GB RAM and no GPU. All the tests were with TensorFlow v1.9.0: from pip, built with portage, and built myself for GPU. The prebuilt pip packages for tensorflow-gpu required an older version of CUDA than the one I had so I didn't test that.
| Steps | 100 | 200 | 300 | 400 | 500 | 600 | 700 | 800 | 900 | AVG |
|---|---|---|---|---|---|---|---|---|---|---|
| PIP | 816.75 | 811.48 | 808.75 | 817.62 | 817.94 | 812.81 | 810.61 | 812.37 | 811.00 | 813.26 |
| SRC | 632.77 | 630.48 | 625.17 | 625.16 | 617.06 | 611.70 | 616.83 | 614.71 | 618.39 | 621.36 |
| GPU | 8.789 | 8.681 | 8.471 | 9.173 | 8.114 | 8.148 | 8.387 | 8.194 | 8.607 | 8.507 |
Times are in seconds per 100 steps on the cifar10 benchmark.
PIP / SRC = 1.31x speedup!
Thats pretty good. Obviously the GPU is way faster but just building TensorFlow yourself already gives huge gains. This is a significant enough speedup that if you want to train a big model, you could start from scratch and compile TF then start training and still be done before just using the pip package. Sort of the modern version of Abraham Lincoln's quote: "Give me six hours to chop down a tree and I will spend the first four sharpening the axe."
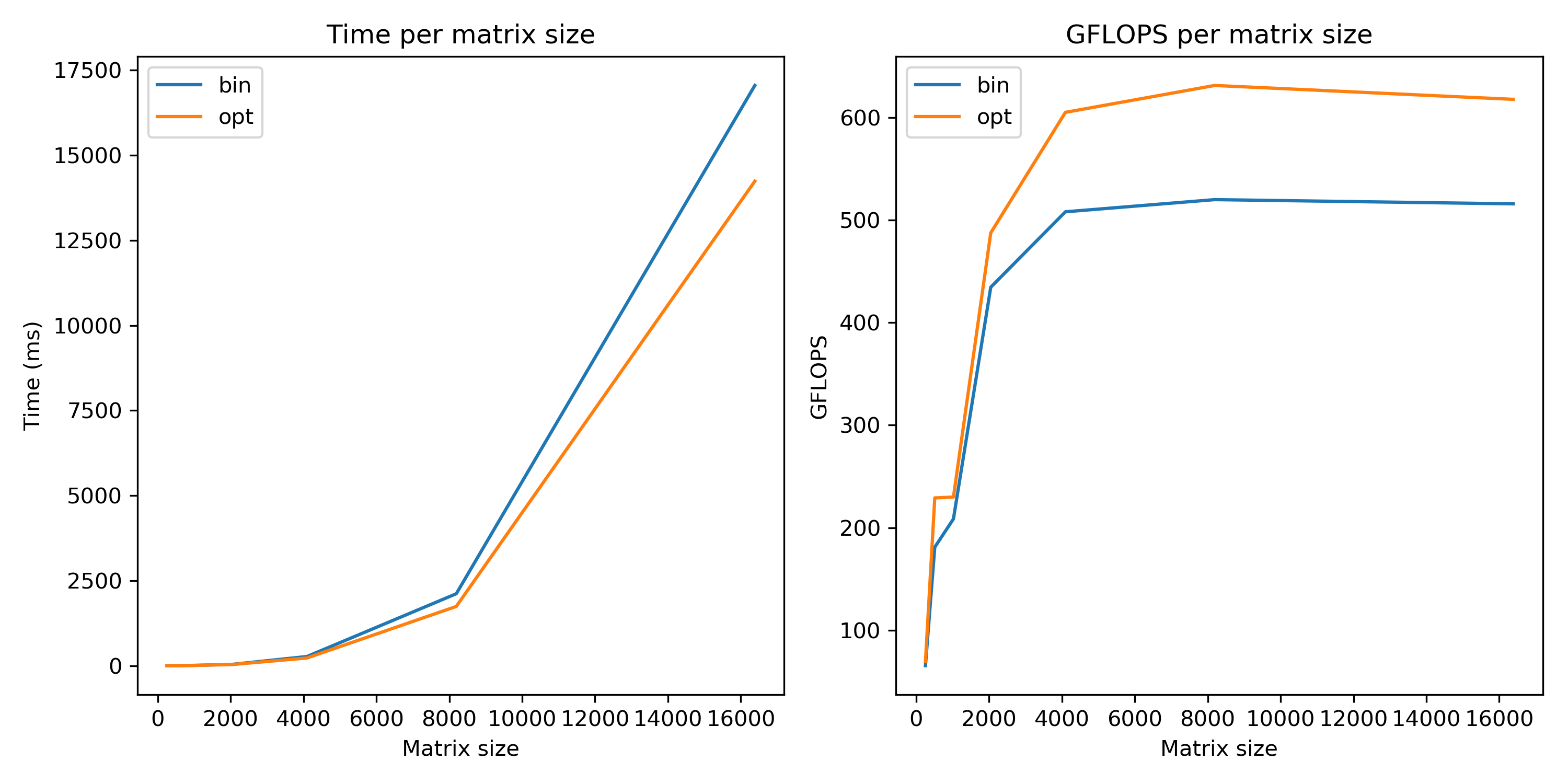
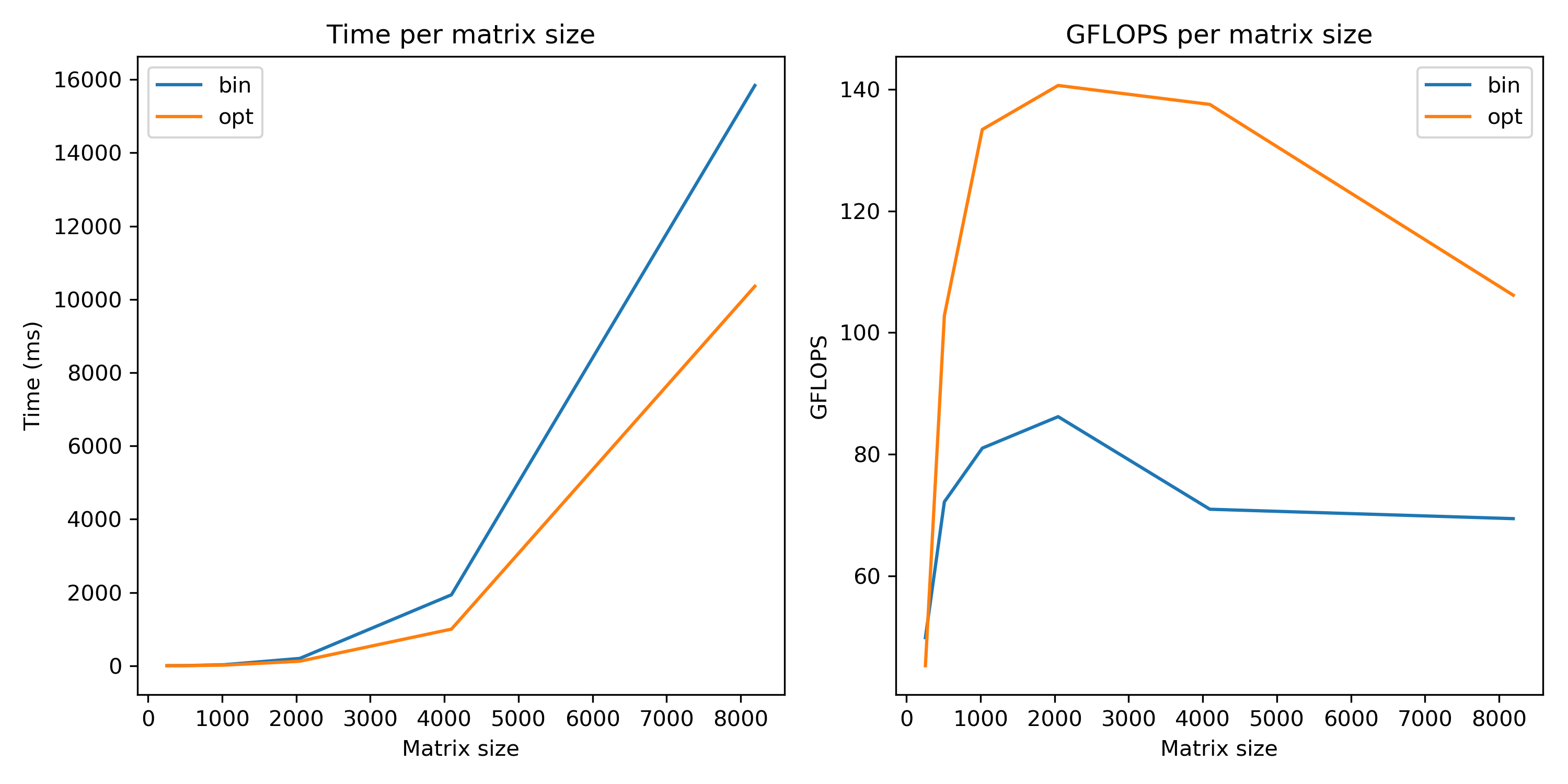
The matrix multiplication benchmark was a tf.matmul() with sizes from 256x256 up to 16384x16384.
Threadripper workstation:
Haswell Laptop:
| Threadripper | Haswell | |
|---|---|---|
| PIP | 519.9 GFLOPs | 86.2 GFLOPs |
| SRC | 631.2 GFLOPs | 140.6 GFLOPs |
| GPU | 11657 GFLOPs | N/A |
Threadripper workstation optimized speedup = 1.22x!
Haswell laptop optimized speedup = 1.63x!
The workstation had a decent speed jump but the laptop's jump was HUGE. The Threadripper seemed fastest at 4k matrix sizes and laptop was fastest at 2k so those are what I used. For 4k sizes on the laptop, optimizing was even better at around 2x.
CPU Extensions
So clearly this makes a huge difference, but why? To answer that we need to go back through computer history a little. Originally CPUs processed things one at a time. If you need to multiply many numbers you load the first two, multiply, save them. Load the next two, multiply, save. repeat over. and over. This is called SISD: Single Instruction, Single Data. This was fine decades ago when Moore's Law and Dennard Scaling worked. In the good old days, computers would double in power every year. Then Moore's Law and Dennard Scaling started to stop working and we moved to the multicore era. Things were still mostly okay, a doubling in compute power would only take 3.5 years. Now all of that is mostly over so we get closer to 3% increase per year.
To get around these limitations, the hardware manufacturers started making specialized extensions to the processors that could process many things at one. This was called Single Instruction, Multiple Data. Originally they were used for multimedia because video needs to play at 24 fps and computers were slow originally. Over time these extensions could do more so now with AVX2 and FMA a processor can do 256-bits worth of calculations at once.
With AVX2 (Advanced Vector
Extensions) a CPU
can multiply two sets of 8 numbers all at once. FMA (Fused
Multiply-Add)
is even better, it can do a = a * b + c all at once where each of a, b, c are
8 32-bit floats. With FMA, AMD processors can theoretically do 16 FLOPs/cycle
and Intel processors can do double that. For my workstation CPU this works out
to be theoretically 16 FLOPs/cycle * 3.4 GHz * 16 cores = 870 GFLOPs, so
the benchmark is pretty good considering thats the absolute maximum theoretical
limit.
AVX has been in processors since ~2011 while AVX2 and FMA have been in processors since Intel Haswell and AMD Piledriver released in ~2012/2013. That means if your computer is less than 5 years old you almost definitely have support for these extensions already. Since TensorFlow 1.6, the pre-built pip packages use AVX but not AVX2 or FMA yet. The point of the pip packages is to work easily, not to give the absolute best performance so not including support for AVX2 and FMA makes sense, it just means for best performance you should build it yourself.
These extensions can be enabled with GCC using the -mavx2 and -mfma
flags. There are other GCC optimization flags that are helpful too: gcc
-O<number> (O the letter, not the number).
- -O0: Turns off optimization entirely. Fast compile times, good for debugging. This is the default if you don't specify any which you probably don't want.
- -O1: Basic optimization level.
- -O2: Recommended for most things. SSE / AVX may be used, but not fully.
- -O3: Highest optimization possible. Also vectorizes loops, can use all AVX registers.
- -Os: Small size. Basically enables -O2 options which do not increase size. Can be useful for machines that have limited storage and/or CPUs with small cache sizes.
There are a lot of these extensions and knowing exactly which to use is
complicated so luckily GCC can figure it out on its own. If you are building
TensorFlow on the same machine that will be running it you can just use -O3
-march=native. If you are building on a different machine, you can use the
command below to see which flags GCC would set and then pass them when
configuring TF. The Gentoo wiki also has some safe
CFLAGS for common CPU types.
# This is the output on my machine:
$ gcc -march=native -E -v - </dev/null 2>&1 | grep cc1
/usr/libexec/gcc/x86_64-pc-linux-gnu/7.3.0/cc1 -E -quiet -v - -march=znver1
-mmmx -mno-3dnow -msse -msse2 -msse3 -mssse3 -msse4a -mcx16 -msahf -mmovbe
-maes -msha -mpclmul -mpopcnt -mabm -mno-lwp -mfma -mno-fma4 -mno-xop -mbmi
-mno-sgx -mbmi2 -mno-tbm -mavx -mavx2 -msse4.2 -msse4.1 -mlzcnt -mno-rtm
-mno-hle -mrdrnd -mf16c -mfsgsbase -mrdseed -mprfchw -madx -mfxsr -mxsave
-mxsaveopt -mno-avx512f -mno-avx512er -mno-avx512cd -mno-avx512pf
-mno-prefetchwt1 -mclflushopt -mxsavec -mxsaves -mno-avx512dq -mno-avx512bw
-mno-avx512vl -mno-avx512ifma -mno-avx512vbmi -mno-avx5124fmaps
-mno-avx5124vnniw -mno-clwb -mmwaitx -mclzero -mno-pku -mno-rdpid --param
l1-cache-size=32 --param l1-cache-line-size=64 --param l2-cache-size=512
-mtune=znver1
Bazel
TensorFlow is built using Bazel a build system Open Sourced by Google based on their internal one called Blaze. It is designed to be fast, scalable, and correct. Fast and scalable I agree with. It is correct for how Google uses it, which is not quite as friendly for how normal distros build things, though features to make it easier to use for distros are on the roadmap.
Once you get used to it, its fairly simple and powerful. The root of the repo
contains a WORKSPACE file, and build targets are declared in BUILD files. There
are tons of docs on the site, but to just build TensorFlow you just need to
know commands look like: $ bazel build //main:helloworld. No, that is not a
typo. Yes, there really are two slashes at the front.
Building TensorFlow is fairly simple, full docs are here but here's a summary.
$ git clone https://github.com/tensorflow/tensorflow.git
$ cd tensorflow
$ git checkout v1.9.0
$ ./configure
Configure will ask many questions, it will build faster if you turn off the
ones you don't need. ./configure is a python script, it has nothing to do
with autoconf. The more important ones to look for are:
Do you wish to build TensorFlow with CUDA support? [y/N]: n
No CUDA support will be enabled for TensorFlow.
Please specify optimization flags to use during compilation when bazel option "--config=opt" is specified [Default is -march=native]: -O3 -march=native
Turn CUDA off if you don't have a GPU, it takes ages to build. The optimization one is where you give it the flags we discussed above. Once its all ready, just run:
$ bazel build --config=opt \
//tensorflow/tools/pip_package:build_pip_package \
//tensorflow:libtensorflow_framework.so \
//tensorflow:libtensorflow.so
$ bazel-bin/tensorflow/tools/pip_package/build_pip_package /tmp/tf/
$ pip install /tmp/tf/tensorflow-*.whl
The --config=opt flag is important otherwise it won't use the optimization
flags you specified. Alternatively, I've done all the work already on Gentoo so
just use: # emerge tensorflow.
If you're using GPUs for TensorFlow you may be wondering why bother with all
this? TensorFlow's gpu packages currently are built for CUDA 9.0, the latest is
9.2. Nvidia GPUs have "Compute Capabilities" which should ideally match your
card. Anything lower will work but you may be missing out features. The
pre-built ones are for "3.5,5.2", you can see what level your card is
here. Also, not everything can run on
a GPU, the input pipeline is all on the CPU so especially if you're training
with lots of fast cards, you'll want the CPU portions to be as optimized as
possible to keep up. When using the Gentoo package, TF will try to autodetect
which capabilities your card has. You can set
TF_CUDA_COMPUTE_CAPABILITIES="6.1" in your make.conf to force a specific
version.
The slides from my talk are here and unfortunately, it was not recorded. The matmul benchmark is on Github. I'd be interested to see results from running it on other systems too.